Uma abordagem de machine learning para o log analytics
As pesquisas, visualizações e dashboards do Kibana são formas muito eficazes de analisar um sistema, mas uma séria limitação das plataformas de log analytics, incluindo o ELK Stack, é a prova de que as pessoas só executam o que sabem. Uma busca no Kibana, por exemplo, é limitada ao conhecimento do operador que a formulou.
Pedir a um assistente pessoal virtual como Alexa, por exemplo, para ajudar no debug de um sistema em produção pode parecer uma ideia encantadora, mas a noção de usar uma abordagem de machine learning é realmente muito viável e prática.
Os algoritmos de aprendizado de máquina têm se mostrado muito úteis nos últimos anos para resolver problemas complexos em muitos campos. Da visão de computador a carros autônomos, esses algoritmos têm fornecido soluções para problemas e resolvido questões onde um dia seriam necessários peritos de carne e osso.

Machine learning supervisionado
Entre as várias abordagens relacionadas ao aprendizado de máquina, o machine learning supervisionado figura como uma das ferramentas mais poderosas na caixa de ferramentas de um cientista de dados.
O machine learning supervisionado baseia-se na ideia de aprender com o exemplo. O algoritmo é alimentado com dados que se relacionam com o domínio do problema e metadados que atribuem rótulos (ou labels) aos dados. Por exemplo, os dados específicos do domínio podem ser uma imagem – essencialmente um conjunto de pixels – e um rótulo. O rótulo pode indicar que o conjunto de pixels forma um carro, um pedestre ou símbolo de trânsito importante. O processo de atribuição de rótulos aos dados é chamado de “labeling“, e desempenha um papel crucial na obtenção de bons resultados no machine learning supervisionado.
Como fazer classificação correta
A questão da relevância do log não é trivial: um log que pode ser muito útil para um usuário pode ser completamente irrelevante para outro. Além disso, no processo de data labeling, logs interessantes podem não ser rotulados corretamente ou serem simplesmente ignorados por estarem perdidos na confusão.
Para resolver o problema da rotulagem de dados, Tomer Levy, desenvolvedor da plataforma de análise de logs Logz.io usa as seguintes metodologias:
Comportamento de usuário implícito e explícito.
“Prestamos atenção às formas como os nossos clientes interagem com as nossas ferramentas. Criar um alerta, criar um dashboard, visualizar um log e outras ações são algumas das tarefas pelas quais nossos usuários indicam o que é importante para eles”.
Semelhanças entre usuários.
“Somos todos muito semelhantes e usamos os mesmos componentes e, portanto, compartilhamos logs semelhantes. Consequentemente, usuários semelhantes podem tirar proveito de um labeling comum”.
Pesquise recursos públicos em comunidades de perguntas e respostas, sites e outros.
Sites como o Stack Overflow, GitHub e até mesmo a Wikipedia hospedam um vasto conjunto de conhecimentos que podem ser usados para avaliar a importância dos logs e até mesmo propor soluções para problemas básicos indicados por esses logs.
A combinação de dados desses recursos permite que a Logz.io crie um conjunto de dados muito ricos de logs rotulados, juntamente com metadados sobre a relevância do log, frequência e, em alguns casos, até mesmo informações que mostram como resolver o problema subjacente.
Treinando o classificador
Uma vez acumulados os dados necessários – registros de log e rótulos correspondentes – é possível construir um classificador de logs.
A classificação pode ser realizada de muitas maneiras, e um dos métodos utilizados é o Linear Support Vector Machines (SVM). Este tipo de classificador oferece treinamento simples e é fácil de interpretar por especialistas em domínio.
Mais informações sobre o SVM e sua aplicação para a classificação de texto podem ser encontradas aqui:
- https://www.cs.cornell.edu/people/tj/publications/joachims_98a.pdf
- https://nlp.stanford.edu/IR-book/html/htmledition/support-vector-machines-and-machine-learning-on-documents-1.html
Para este exemplo, um vetor precisa ser construído. Usar n-grams curtos normalmente gera um espaço de recursos de uma dimensão de cerca de 1M de dimensões, o que é viável e rico o suficiente para dar bons resultados.
Exemplos de tais n-grams e respectivos coeficientes são apresentados abaixo. Como pode se ver, é muito fácil interpretar os resultados e verificá-los posteriormente. Valores positivos indicam algum tipo de falha do sistema, enquanto valores negativos indicam um registro de log que não contém um estado relevante e acionável.
unable: 0.671539714688 topic: 0.678756599452 error: 0.788508324168 connected: -0.157199772246 to provider: -0.15319903564 connected successfully: -0.15319903564
Outra possibilidade de treinar um classificador é usar as Random Forests, que são muito úteis nos casos em que as características são categóricas (não numéricas) e não se encaixam perfeitamente nos modelos lineares. Mais informações sobre o uso de Random Forests para classificação podem ser encontradas aqui:
https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
Embora aparentemente trivial, este processo é muito poderoso. Não é preciso um especialista para dizer que “erro” é uma frase que pode indicar uma questão de produção, mas é praticamente impossível mesmo para a melhor equipe DevOps encontrar as correlações e relações entre um milhão de frases que ocorrem no log de dados. O processo de alimentar essas vastas quantidades de dados para o machine learning supervisionado permite que a máquina aprenda com o conhecimento acumulado de centenas de equipes DevOps e centenas de milhares de contribuintes de sites relacionados.
“Na Logz.io, usamos um conjunto de algoritmos de aprendizado de máquina que são capazes de coletar bits e pedaços de dados – principalmente sobre o que mais importa aos usuários em seus dados de log – e fazemos a fusão de tudo junto em um processo supervisionado que treina nosso código de machine learning. Uma das partes mais poderosas do sistema de aprendizagem da Logz.io é que ele aprende a partir da maneira como os usuários reagem a esses eventos destacados, permitindo a supervisão e aprendizado contínuos”, conta Tomer Levy.
Integração
“Uma vez treinado o classificador, ele foi integrado ao pipeline da Logz.io. Nós usamos ferramentas, incluindo Spark e Hadoop, para executar o classificador e a aprendizagem de máquina na escala necessária. Os logs que passam por toda a fase de classificação são rotulados como ‘Insights Cognitivos’ e informações adicionais que foram coletadas na fase de rotulagem estão anexadas a eles. Isso permite não só destacar os logs relevantes para os clientes, como também enriquecer os logs com informações adicionais”, explica Levy.
Um exemplo de classificação
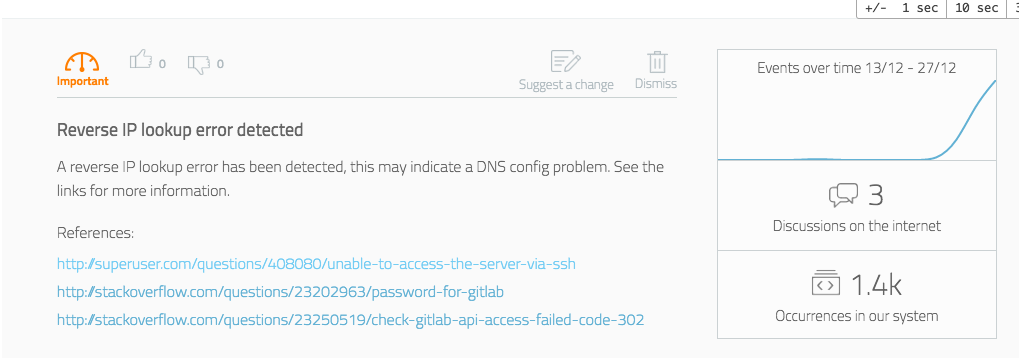
Obviamente, a tecnologia de aprendizado da Logz.io é muito mais complicada e inclui uma análise multi-vetor, mas compartilhamos um exemplo simplificado. O seguinte log foi analisado no sistema (valores específicos foram omitidos):
“Address <strong>IP_OCTET</strong> maps to <strong>URL</strong>, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!”
O nível de log para este log não era alto, não continha nenhuma das frases de erro habituais, triviais (“erro”, “fatal“, “exceção”, etc.), mas foi classificada como interessante.
O log foi então passado através do módulo de aumento, e foram encontrados vários tópicos relevantes em sites especializados:
- https://superuser.com/questions/408080/unable-to-access-the-server-via-ssh
- http://stackoverflow.com/questions/23202963/password-for-gitlab
- http://stackoverflow.com/questions/23250519/check-gitlab-api-access-failed-code-302
As fontes indicam que, ao contrário do texto do log, é mais provável que seja um problema de DNS do que uma ameaça de segurança real.
O sistema então exibe o log e os dados para o usuário de maneira informativa:
Em resumo
Utilizar uma abordagem de aprendizado de máquina para análise de log é uma maneira muito promissora de tornar a vida mais fácil para engenheiros DevOps. A classificação de logs relevantes e importantes usando o aprendizado de máquina supervisionado é apenas o primeiro passo para aproveitar o poder das comunidades e do Big Data no log analytics. O cluster de log adaptativo, a recomendação de log, e alguns outros recursos interessantes estarão disponíveis dentro em breve, fique atento!
Fonte: DZone.com
Gostou do conteúdo? Tem alguma dúvida? Entre em contato com nossos Especialistas Mandic Cloud, ficamos felizes em ajudá-lo.