Teste Contínuo é crucial para o DevOps, mas não é tarefa fácil
À medida que o software passa de uma arquitetura monolítica para uma arquitetura de microsserviços, as organizações têm adotado práticas DevOps para acelerar a entrega de recursos aos clientes e melhorar suas experiências.
Passar para testes contínuos sem a infraestrutura, ferramentas e processos corretos pode ser um desastre. O teste contínuo desempenha um papel importante para alcançar a mais rápida qualidade no mercado. O teste contínuo requer diversos níveis de monitoramento, com triggers automáticos, colaboração e ações. Descreveremos neste post os 4 pontos principais para um cenário bem sucedido:
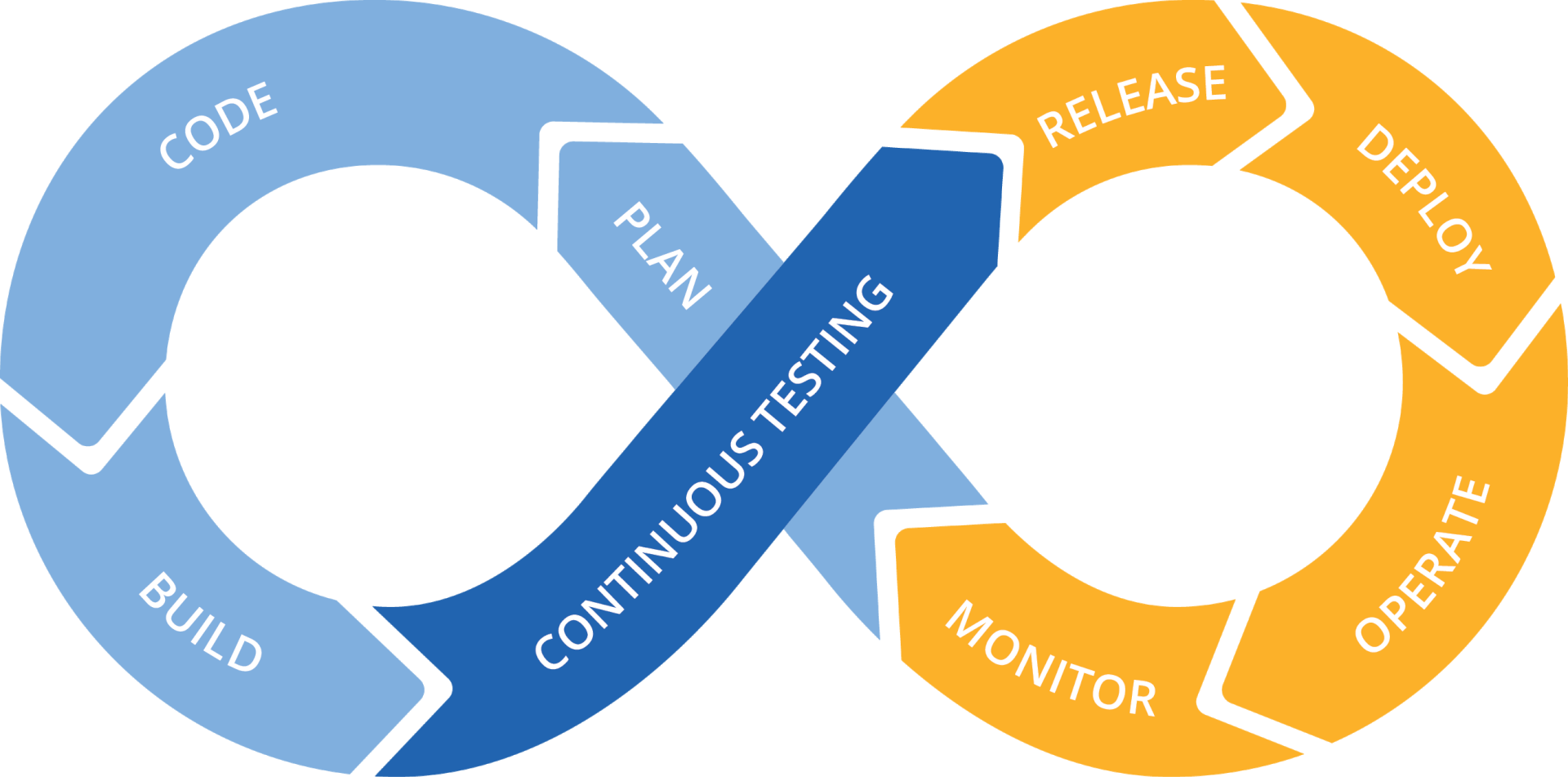
Automatic Test Triggers para executar testes como transições de software entre vários estágios – desenvolvimento / teste / montagem / produção.
Service Health Monitoring para automatizar comentários sobre falhas
Test Result Monitoring para automatizar comentários sobre falhas
Identificação da causa raiz da falha e análise dos resultados dos testes
#1 Automatic Test Triggers
Para permitir um feedback mais rápido, os testes precisam ser classificados em várias camadas:
Health Check – O foco desses testes é garantir que os serviços estejam funcionando. Essas verificações são desencadeadas por vários aplicativos de monitoramento.
Smoke Test – O foco desses testes é verificar se os principais recursos comerciais são operacionais e funcionais. Esses testes devem ter um ciclo de teste curto, geralmente inferior a 15 minutos e executado em forma contínua.
Regressão Inteligente – Este subconjunto dos cenários do teste de regressão é desencadeado com base nas alterações de código com implementações, e uma regressão completa é acionada para ser executada durante a noite.
Benchmark/Load Test – O foco desses testes é medir o desempenho de cada serviço, sendo acionados para serem executados durante a noite.
Confiabilidade/Teste de Caos – O foco desses testes é medir o comportamento do sistema, enquanto as falhas são intencionalmente injetadas nos serviços. Tais testes são desencadeados semanalmente para identificar problemas cruciais de infraestrutura ou operacionais.
#2. Service Health Monitoring
Manter a saúde dos serviços requer:
Alertas Automatizados – A automação notifica a equipe de serviço em questão para tomar as medidas adequadas exigidas para corrigir a falha.
#3. Test Result Monitoring
À medida que os testes são acionados, é essencial monitorar os resultados e tomar as medidas necessárias quando são detectadas falhas no ambiente:
Notificações Automatizadas – Notifica as equipes de desenvolvimento de serviços para tomar as ações necessárias, como bloquear o lançamento em produção se um defeito crítico for introduzido.
#4. Identificando a causa raiz da falha
Configure um framework para rastrear cada request usado para executar testes automatizados e como esses requests atravessam os vários serviços distribuídos:
Identificação de informações – Todo request feito para executar testes de automação inclui um cabeçalho personalizado que contempla informações como Test Run ID ou Test Case ID. Após a submissão do request, a resposta conterá os IDs de rastreamento do aplicativo que você pode acompanhar nos logs de resultados do teste.
Cada erro de teste desencadeia um processo de investigação automatizado que faz o seguinte:
- Recupera os detalhes do caso de teste para identificar a lista de componentes testados nos respectivos testes.
- Identifica se algum dos componentes foi alterado desde a última execução de teste bem-sucedida.
- Identifica a lista de alterações e recupera as métricas para cada um desses componentes.
- Correlaciona os resultados do teste com base nas alterações para identificar um padrão.
- Uma vez identificado o problema, atualiza os proprietários das equipes de serviço para tomar as medidas necessárias e corrigir o problema.
Fonte: DZone.com
Gostou do conteúdo? Tem alguma dúvida? Entre em contato com nossos Especialistas Mandic Cloud, ficamos felizes em ajudá-lo.