Facebook desenvolve modelo de rede neural eficiente sobre 1 bilhão de palavras
Usar redes neurais para previsão de sequências é um problema conhecido da Ciência da Computação, com uma vasta gama de aplicações em reconhecimento de voz, tradução automática, modelagem de linguagem e outros campos. Os modelos em uso são computacionalmente exigentes, o que limita sua aplicabilidade prática.
Mas os cientistas do Facebook AI Research conseguiram desenvolver uma função softmax adaptável, qual seja, um algoritmo de aproximação adaptado para GPUs e que pode ser usado para treinar eficientemente redes neurais em grandes vocabulários. O softmax adaptativo, como descrito no artigo publicado, explora a distribuição desequilibrada de palavras sob um grande corpora (“corpus linguístico”) para formar clusters que podem minimizar a expectativa de complexidade computacional. O softmax completo tem uma correlação linear com o tamanho do corpus do vocabulário, enquanto o softmax adaptativo é sublinear e otimizado para uso da GPU.
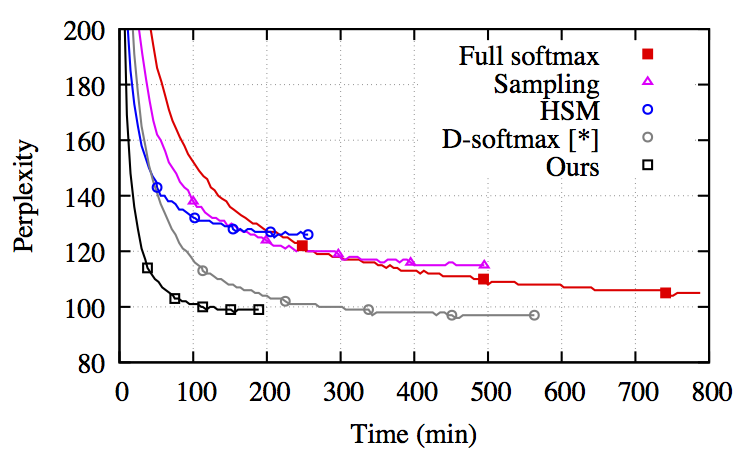
Convergência entre modelo de linguagem e diferentes aproximações softmax
Em conjunto com o desenvolvimento do softmax adaptativo, os pesquisadores do Facebook anunciaram o torch-rnnlib, uma biblioteca de código aberto para projetar e testar modelos recorrentes em GPUs. O torch.cudnn permite fácil acesso às baselines usando a biblioteca NVIDIA CUDA Deep Neural Network. RNN, LSTM, GRU e outras redes recorrentes estão implementadas e podem ser facilmente utilizadas pelos pesquisadores como building blocks para projetar redes neurais recorrentes.
Ao testar o algoritmo em uma única GPU, os pesquisadores do Facebook conseguiram 12.500 palavras/segundo enquanto mantinham a precisão perto do limite do softmax. As perplexidades alcançadas no benchmark realizado pelos pesquisadores foram 30, pelo Google Jozefowicz et al, 2016 usando 32GPUs durante três semanas e 44 usando 18GPUs. A implementação do Google do modelo LSTM usando Tensorflow está disponível no Github e o autor oferece uma explicação interessante do desempenho de perplexidade em uma thread relevante no Reddit. Em contraste, o softmax adaptativo pode chegar a uma perplexidade de 50 dentro de aproximadamente 14 horas, de 43,9 em alguns dias e de 39,8 em seis dias. Sem a biblioteca CuDNN, o desempenho cai para aproximadamente 30%. Todas as ferramentas e técnicas foram testadas com os corpus EuroParl e One Billion Word, que estão entre os maiores disponíveis.
Fonte: InfoQ
Gostou do conteúdo? Tem alguma dúvida? Entre em contato com nossos Especialistas Mandic Cloud, ficamos felizes em ajudá-lo.