Lambda AWS para desenvolvedores Java serverless: como melhor aproveitá-lo?
A arquitetura serverless computing vem ganhando atenção durante os últimos anos, por ser focada em um dos principais componentes em um aplicativo: os servidores. Essa arquitetura apresenta uma abordagem diferente.
Neste post, Henn Idan, do DZone, explica o que é ser serverless, suas características principais, e como se aplica em cada situação:
A nova roupagem da nuvem
O conceito de computação serverless versa sobre deploy de código, e não de servidores. Pode parecer um pouco confuso no início, pois implica que seria possível descartar os servidores de uma forma geral e executar um aplicativo sem eles. Mas, não é bem o que acontece.
Em vez de comprar, gerenciar e escalar, o provedor de nuvem é quem cuida das requisições feitas às VMs. Então, o usuário ainda precisa de servidores, mas este novo modelo não lhe delega essa responsabilidade. Ou, em outras palavras, não há problema em lidar com deploys em servidores ou instalações de software de quaisquer tipos. Basicamente, tudo o que o usuário precisa é de um serviço de nuvem gerenciado e um computador.
Por dentro do Lambda AWS
Esse modelo foi introduzido pela primeira vez pela Amazon, em 2014, como Lambda AWS. A empresa foi a primeira a oferecer o serverless como serviço – como parte da suite Amazon Web Services.
O Lambda AWS é baseado em uma plataforma orientada e desencadeada por eventos tais como inscrições, atualizações e assim por diante. Quando um evento acontece, irá chamar as funções relevantes que, por sua vez, executarão o código. Tudo isso ao mesmo tempo em que acontece o gerenciamento e processamento dos recursos necessários para executar, e usando apenas esses recursos.
Em outras palavras, o workflow básico permanece o mesmo: escrever o código, fazer o upload para um servidor para que seja executado, e remover as preocupações sobre tempo de resposta, operações, e assim por diante.
O Lambda é muitas vezes referido como “Function as a Service (FaaS)”, ou “recurso como serviço”, uma vez que os eventos acionam as funções relevantes necessárias para proceder com as requisições, o que permite executar funções sem maiores incômodos.
Juntamente com a FaaS, a arquitetura serverless também é conhecida como “Backend as a Service (BaaS)”, o que remove uma parte significativa da sobrecarga de administração de banco de dados e oferece autorização para usuários e níveis diferentes.
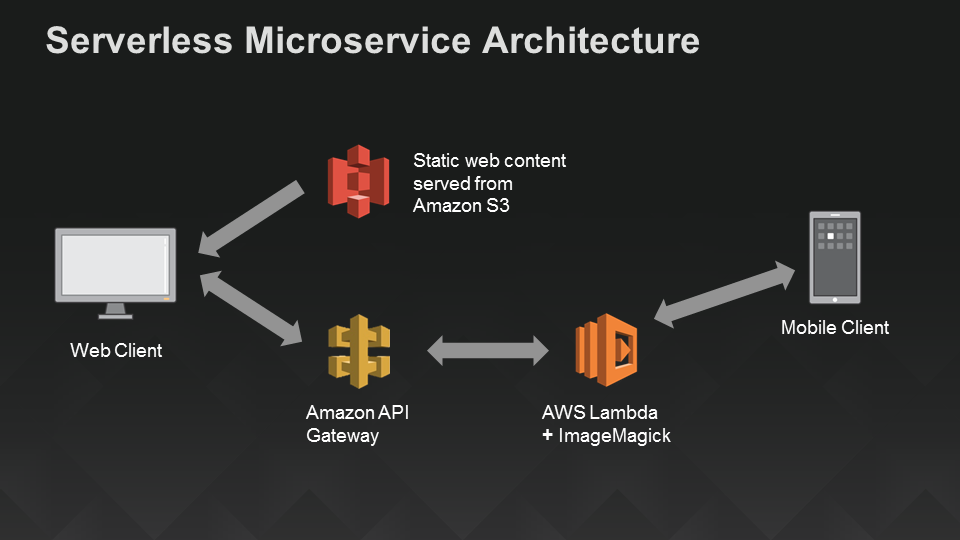
Tim Wagner, Gerente Geral do Lambda AWS, compartilhou um diagrama que ilustra os componentes e suas conexões: uma função Lambda como o recurso de computação (“backend“) e um aplicativo móvel que se conecta diretamente a ele, além da Amazon API Gateway, que fornece um HTTP endpoint para um site estático hospedado na Amazon S3:
Cuidando do código
O principal objetivo do Lambda é permitir que os desenvolvedores criem aplicativos menores, sob demanda, e que respondem a eventos de uma forma simples. Ele funciona para o usuário e gerencia a “frota de computação” balanceando memória, CPU, rede, aplicação de patches de segurança, monitoração do funcionamento e quaisquer outros recursos e ações necessárias.
Uma boa maneira de olhar para ele é como um serviço de outsourcing. Não só ele “realoca a TI“, mas pode até mesmo ajudar a reduzir custos operacionais, na medida em que remove custos de infraestrutura e até mesmo reduz a quantidade necessária de membros da equipe para manter os servidores.
Sobre custos, o usuário só paga pelo que consome, com base no número de requisições de suas funções e no tempo em que seu código executa. E é importante afirmar que a camada gratuita inclui 1 milhão de requisições livres por mês e até 3.2 milhões de segundos de computação por mês.
O cálculo de cada requisição é contado a partir de quando começa a executar como uma resposta a um evento ou invoca uma chamada. O que também inclui testes do console.
De acordo com a Amazon, o Lambda AWS é a plataforma para muitos cenários de aplicação. Mas, claro, há um porém: essa afirmação só é relevante para os idiomas suportados pelo Lambda AWS: Node.js, Java e Python. Portanto, muito cuidado com isso.
No lado positivo, construir funções Lambda AWS com Java pode ser feito com as ferramentas que o usuário já conhece, Maven ou Gradle, e o processo de construção permanece praticamente o mesmo.
“Show me the code”
Invocar uma função Lambda AWS é muito fácil após uma configuração básica e o usuário pode acompanhar a explicação completa aqui.
Ela inclui a definição dos POJOs, que representam a entrada e saída JSON, especificando uma interface que representa o microserviço, anotando-o com o nome da função Lambda para invocá-lo quando for chamado.
O próximo passo será usar LambdaInvokerFactory para criar uma implementação dessa interface. Isso nos permitirá fazer chamadas para o serviço que está em execução no Lambda. Então podemos simplesmente invocar o serviço usando esse objeto proxy, como… “counting cats”:
CountCatsInput input = new CountCatsInput();
input.setBucketName("pictures-of-cats");
input.setKey("three-cute-cats");
int cats = catService.countCats(input).getCount();
Antes de começar…
Claro, nada é perfeito, e a opção de focar principalmente no código vem com alguns inconvenientes. Como se trata de uma tecnologia ainda muito recente, é fácil encontrar uma lista de problemas que no deixam os usuários muito felizes, tais como:
Controle: Estamos “deixando de lado” os servidores na esperança de que o provedor de cloud irá cuidar da questão da melhor maneira possível. Mas, com isso, podem surgir problemas centrais sobre os quais será preciso aguardar até que sejam resolvidos, o que pode pode acarretar tempo de inatividade e clientes insatisfeitos.
Locked-in: Falando em entregar tudo ao provedor de cloud, usar o Lambda AWS significa que o usuário terá que usar AWS. Pode não ser um problema agora, mas ele vai se tornar um, se houver a intenção de migrar para o Google ou simplesmente usar servidores próprios.
Flexibilidade: O usuário não será capaz de logar em instâncias de computação, ou ainda personalizar o sistema operacional ou o tempo de execução do idioma.
Segurança: Usar um terceiro também significa usar sua segurança. Isso NÃO significa que a AWS não seja segura, mas que o usuário está passando a responsabilidade por completo a terceiros, o que pode ser inferior ao ideal.
Monitoramento: Com o AWS Lambda, o usuário pode monitorar e fazer o debug no sistema só com a ferramenta interna CloudWatch. Embora possa criar alarmes personalizados, visualizar taxas de requisição e taxas de erro – é uma ferramenta muito básica, e pode não ajudar a compreender a causa raiz dos problemas.
E essa é apenas uma pequena (mas importante) parte das desvantagens da arquitetura serverless no momento. Também é importante salientar que, se o usuário já possui um aplicativo e gostaria de migrá-lo para uma arquitetura serverless, deparar-se com a possibilidade de escrevê-lo a partir do zero. Portanto, terá que pensar a respeito ou simplesmente fazer o backlog para o próximo aplicativo que estiver pensando em trabalhar.
Pensamentos finais
A Amazon iniciou o movimento serverless com a Lambda AWS e, hoje em dia, outras grandes empresas como a Microsoft, Google e IBM oferecem o modelo, bem como as pequenas empresas e startups.
Se pudéssemos apostar, diríamos que a arquitetura serverless é o futuro. Se o usuário pensar a respeito, verá que é o próximo passo na evolução da computação em nuvem e que leva a depositar a confiança total na nuvem e em seus provedores, do que em si mesmo.
Por enquanto, porém, é melhor se agarrar à nuvem atual ou servidores on-premises. É ainda uma tecnologia muito nova e há algumas questões pendentes que a Amazon, o Google e demais provedores precisam resolver antes que seja possível abandonar os servidores. Podem ser pequenos passos, mas caminhamos nessa direção, gostemos disso ou não.
Fonte: DZone.com
Gostou do conteúdo? Tem alguma dúvida? Entre em contato com nossos Especialistas Mandic Cloud, ficamos felizes em ajudá-lo.