Kubeflow: aprendizado de máquina nativo na nuvem com o Kubernetes
O aprendizado de máquina transformou completamente o cenário da computação, conferindo novos cenários a serem abordados x tornar os cenários existentes muito mais eficientes. No entanto, para ter uma solução de aprendizado de máquina altamente eficiente, uma empresa deve assegurar que inclua os 3 conceitos a seguir: composibilidade, portabilidade e escalabilidade.
3 desafios do aprendizado de máquina
Composibilidade
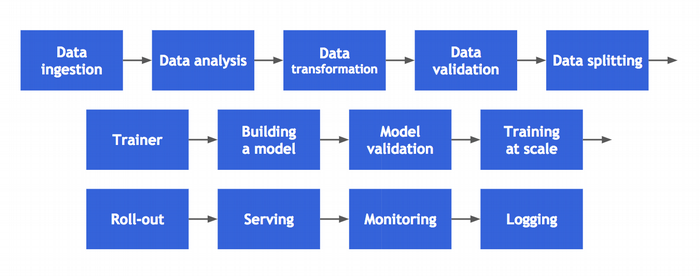
Quando a maioria das pessoas ouve falar de aprendizado de máquina, costuma pular direto para a construção de modelos. Existem vários frameworks muito populares que facilitam muito esse processo, como o TensorFlow, PyTorch, Scikit Learn, XGBoost e o Caffe. Cada uma dessas plataformas é projetada para facilitar o trabalho dos cientistas de dados à medida que exploram o espaço do problema.
No entanto, no contexto da construção de uma solução em nível de produção real, há muitas outras etapas mais complexas. Estas incluem importar, transformar e visualizar os dados; construir e validar o modelo; treinar o modelo em escala; e fazer o deploy do modelo para produção. Concentrar-se apenas no treinamento do modelo desperdiça grande parte do esforço diário de um cientista de dados.
Portabilidade
Para citar Joe Beda, “Cada diferença entre dev/staging/prod acabará resultando em uma interrupção”.
As diferentes etapas do aprendizado de máquina geralmente pertencem a sistemas totalmente diferentes. E como se não bastasse, para tornar as coisas ainda mais complicadas, componentes de nível inferior, como hardware, aceleradores e sistemas operacionais, também são considerados no conjunto, o que aumenta a variação. Sem sistemas e ferramentas automatizadas, essas mudanças podem se tornar rapidamente complicadas e desafiadoras de gerenciar. Essas mudanças também tornam muito difícil obter resultados consistentes de experimentos repetidos.
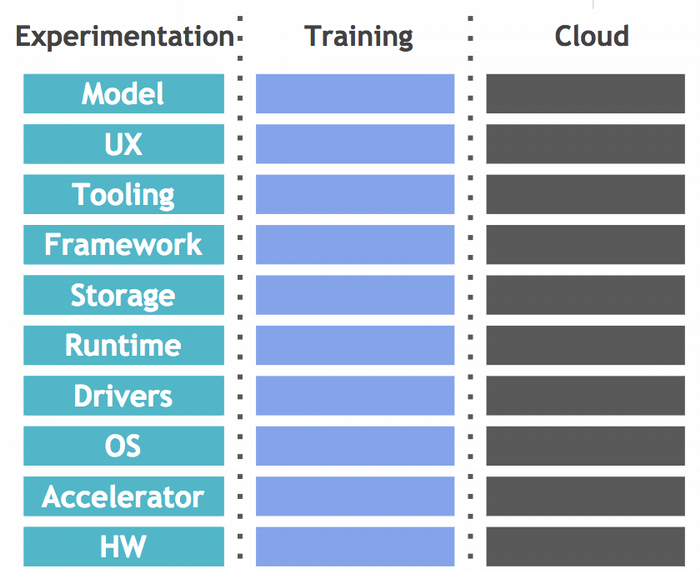
Escalabilidade
Um dos maiores avanços recentes no aprendizado de máquina (deep learning) é resultado da maior escala e capacidade disponíveis na nuvem. Isso inclui uma variedade de tipos de máquinas e aceleradores específicos de hardware – por exemplo, unidades de processamento gráfico/unidades de processamento Tensor – bem como localidade de dados para desempenho aprimorado. Além disso, a escalabilidade não é apenas sobre seu hardware e software; Também é importante poder dimensionar as equipes por meio de colaboração e simplificar a execução de um grande número de experimentos.
Kubernetes e o aprendizado de máquina
O Kubernetes tornou-se rapidamente a solução para fazer o deploy de cargas de trabalho complicadas em qualquer lugar. Embora tenha iniciado a partir de serviços stateless simples, aos poucos os clientes passaram a migrar cargas de trabalho complexas para a plataforma, se beneficiando das ricas APIs disponíveis, da confiabilidade e sobretudo do desempenho avançados fornecidos pelo Kubernetes.
A comunidade de machine learning está começando a usar os benefícios principais; infelizmente, a criação desses deploys ainda é complicada e requer um mix de soluções de diferentes fornecedores e habilidades manuais de código. Conectar e gerenciar esses serviços para configurações moderadamente sofisticadas introduz enormes barreiras de complexidade para os cientistas de dados que estão apenas procurando explorar um modelo.
Apresentando o Kubeflow
O projeto Kubeflow foi criado no final de 2017 para enfrentar esses desafios. A missão do Kubeflow é facilitar o desenvolvimento, deploy e gerenciamento de um aprendizado de máquina compostável, portável e escalonável no Kubernetes, em todos os lugares.
O Kubeflow reside em um repositório livre no GitHub dedicado a tornar as pilhas de aprendizado de máquina no Kubernetes fáceis, rápidas e extensíveis. Este repositório contém:
– JupyterHub para treinamento colaborativo e interativo
– Um treinamento custom resource do TensorFlow
– Uma implementação de serviço do TensorFlow
– Argo para fluxos de trabalho
– SeldonCore para inferências complexas e modelos Python sem TensorFlow
– Reverse proxy (Ambassador)
– Conectores para fazer funcionar em qualquer lugar de qualquer Kubernetes
Como essa solução depende do Kubernetes, ela é executada sempre que o Kubernetes é executada. Basta rodar um cluster e pronto!
Quer experimentar o Kubeflow agora mesmo no seu navegador? Acesse https://www.katacoda.com/kubeflow
O vídeo abaixo mostra o uso do Kubeflow no OpenShift:
Outras referências:
Slack channel
Lista de e-mails do kubeflow-discuss
Fonte: opensource.com
Gostou do conteúdo? Tem alguma dúvida? Entre em contato com nossos Especialistas Mandic Cloud, ficamos felizes em ajudá-lo.